Building a tree-walk interpreter from scratch in Go
A while ago, I read this article called Challenging projects every programmer should try [1]. The article, obvious from its name, lists down a bunch of projects that a programmer can build either to learn some new concepts in a project-oriented way or build them just for the love of the game.
I like exploring different domains with the intent of gaining breadth of experiences. So, reading that article, one of the areas that I found quite interesting was compilers, particularly for gaining clarity on a few confusions I had throughout writing code and executing it: how does the high level code compiles into binary format? Or in other words: how can a blob of text make sense to the computer? (without the syntax highlighting and fancy IDE support, code is just a piece of text)
To clear this confusion, I chose to write a compiler, or rather an interpreter. They are both essentially built upon similar principles: the core difference between them is their approach of program execution. Without any prior knowledge of this area, I went ahead with the Crafting Interpreters book [2] by Robert Nystrom to build a tree-walk Interpreter. The book originally used Java for writing the interpreter but I decided to write it in Go language (wanted to explore Go). The language designed in the book is originally called jLox (J - Java), so I guess we can call it gLox (g - go) in our case.
Tree-walk interpreter
Tree-walk interpreter is a type of interpreter that fits the age old definition of an interpreter:
a program that directly executes the source code, without converting it into machine code.
Whereas a standard interpreter generally translates the source code into an optimized bytecode (like JVM), and then executes the bytecode linearly. Though, the tree-walk interpreter too converts the source code into an intermediary representation i.e. an Abstract Syntax Tree (AST), but it simply does so by parsing (see the process for more details).
Process
To give an overview, the initial process of both interpreters and compilers is similar. It comprises of a few steps:
1. Tokenization (Lexical Analysis)
The source code or the meaningless piece of text is scanned and converted into a collection of tokens by splitting them based on some pre-determined rules.
How are the tokens determined and what do they embody?
Well, tokens for the source language are defined beforehand. In our case, gLox language has bunch of tokens like: while, literal, for, string, number, function etc. representing the possible syntax our interpreter can work with.
Tokenization is based on the usage of state machines, a concept we stumble across often, because a large number of programs (that involves input in textual form) are built using state machines (http servers, serializers, etc., most of the programs that involves parsing/sanitizing the user input)
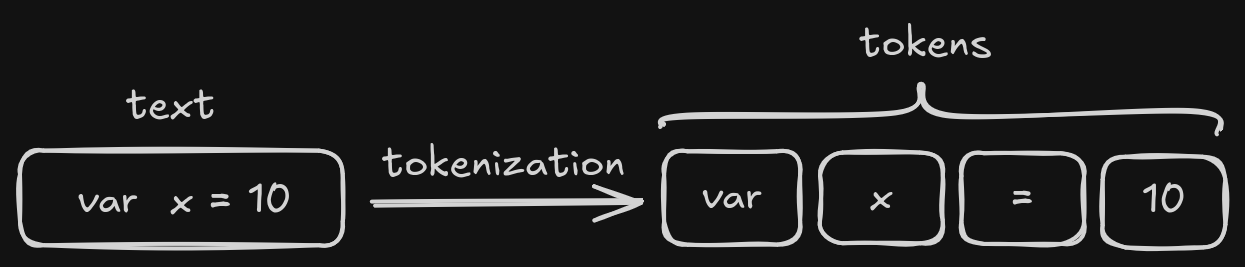
The result is a list of tokens generated from the source code. Tokens also encompass meaningful details like the line of source code it belongs to, which comes in handy during error handling.
2. Parsing
Once the source code is converted into tokens, the next step is to give those tokens a structure. This is the job of a parser.
Parsing transforms the tokens into an intermediary representation called an Abstract Syntax Tree (AST). The AST, as its name suggests, is a tree-based structure with its nodes being executable code i.e. statements or expressions.
The following statement's AST would look like:
sum = 1 + 2
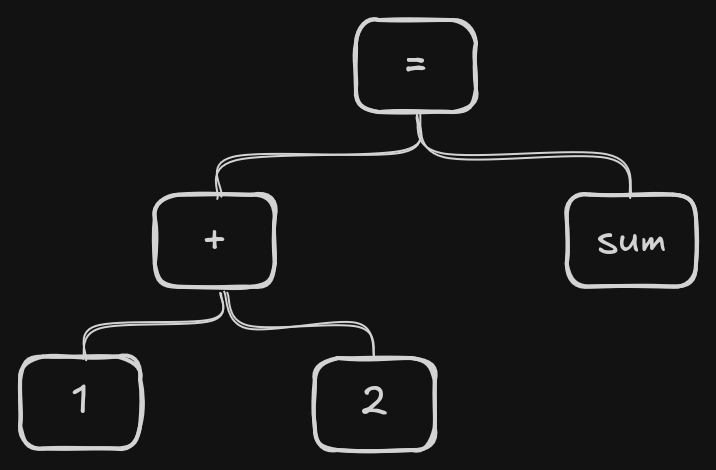
The parser uses grammatical rules (such as context-free grammar) to construct the AST. These rules define what combinations of tokens are part of a valid grammar. For example, do we allow:
-
--1(a minus sign i.e. a unary operator followed by another minus sign) -
1 + 2 - 3(which expression is to be executed first,1 + 2or2 - 3)
These questions are resolved by defining operator precedence and certain rules in the grammar.
In practice, many interpreters (including this one) use a technique called recursive descent parsing, where each grammar rule is implemented as a function. The parser walks through the token list, calling functions that build AST nodes. If the tokens violate the grammar, the parser raises a syntax error, using metadata (like line number) stored during tokenization.
3. Evaluation
Evaluation is the process of walking the generated AST (this is where it got the name tree-walk interpreter from) and produces output in the form of values or side-effects.
The execution of statements and expressions follows the pattern of the defined AST's. It starts with the root node and proceeds recursively downwards using tree traversal. Each node has execution logic for example:
- A literal, being the lowest form of expression, can not be executed further and evaluates to its own value.
- A binary expression evaluates its left and right operands, and then applies the operator.
- A variable node looks up and defines its value in the current environment.
- A function may modify program state, evaluate to some value, or produce side effects.
Interesting Details
This was kind of an abstract overview of the working of an interpreter. And there goes a lot more that I haven't gone over in this blog, such as:
-
Error handling: If the syntactic structure of code goes against the grammar rules, an error is raised at that node using the tokens' metadata. This is how the IDEs we use pinpoint the error location i.e. line and character where an error has occurred. Errors can be static (before execution, related to syntax) and runtime (during execution, related to logic).
--> src/main.rs:21:17 | 21 | let sum = 3 + "1"; | ^ no implementation for `{integer} + &str` | -
Closures: Closures are functions that remember the environment in which they were created. When a function is defined inside another scope, it may reference variables that are not local to it. Instead of losing access to those variables after the outer scope finishes execution, the function keeps a reference to them.
fun makeCounter() { var count = 0; fun increment() { count = count + 1; print count; } return increment; } var counter = makeCounter(); counter(); // 1 counter(); // 2Here,
incrementcontinues to access count even aftermakeCounterhas returned. This works because the function captures the surrounding environment at the time of its declaration. -
Problem of mutable and persistent environments: Implementing closures introduces an important design question: what exactly should a closure capture?
Consider this example:
var a = "global"; { fun showA() { print a; } showA(); // "global" var a = "block"; showA(); // ? }Should both calls print "global"? Or should the second call print "block"?
The correct behavior is that both calls print "global", because the function should bind to the variable that was visible at the time of declaration, not whatever variable exists later during execution. This leads to the distinction between:
Mutable environments (where variables can change over time) and Persistent environments (where closures keep references to the correct scope chain)
Solving this properly requires a variable resolution phase before execution, which determines how many scopes away a variable lives. That way, the interpreter can reliably access the intended variable even if new variables with the same name are declared later.
-
Language Design decisions: a cool part of writing an interpreter / compiler is to decide how the language should work under certain conditions. Like the choice of truthy values is upto your liking: e.g.
1is truthy and0is not. However, if"0"as a string should be a truthy value is upto you to decide. In JavaScript"0"is loosely equal to a falsy value, whereas most other languages are designed to consider any non-empty string to be a truthy value.
Links
The code for the interpreter can be found on my GitHub repository.